
Linux 系统编程 文件篇 (三) 重定向、一切皆文件与文件缓冲区
[TOC]
Linux 系统编程 文件篇 (三)
1. 重谈重定向
开始之前呢,补充一个上一篇漏下的点。一个文件可不可以被多个进程打开?
当然是可以的,但是如果一个文件被多个进程打开,其中一个进程把这个文件关了,会不会影响别的进程?不会的。为什么呢?因为有这个引用计数,一个文件被打开后这个引用计数就 ++ ,关闭引用计数就 –。当这个文件引用计数为 0 的时候,操作系统再去把对应的空间释放掉。虽然我们没有自己动这个引用计数,但是我们在重定向或者关闭文件的时候用的都是系统调用,它自己就给我们办了。
1.1 标准错误
我们之前老是说标准输入,标准输入和标准输出,分别对应的是键盘文件,显示器文件和显示器文件。标准输入和标准输入我们平时都用,比较熟悉,那么这个标准错误呢?
首先既然它对应显示器文件,也就是往里面写东西同样会出现在显示器上:
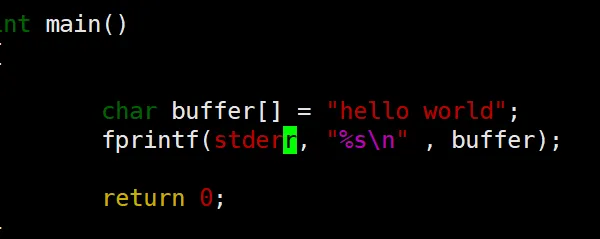

C++ 里面cin 输入,cout 往显示器上输入,同样 cerr 也是往显示器上输出。

1.2 再谈重定向
我们之前重定向的用法是这样的:

其实,重定向完整的写法应该是这样的:
1 | ./myproc 1 > log.txt |
对应的就是我们把 log.txt 里面的东西拷贝到 1 ,也就是标准输出里面。
如果我们想把标准输入和这个标准输入都重定向一下呢?
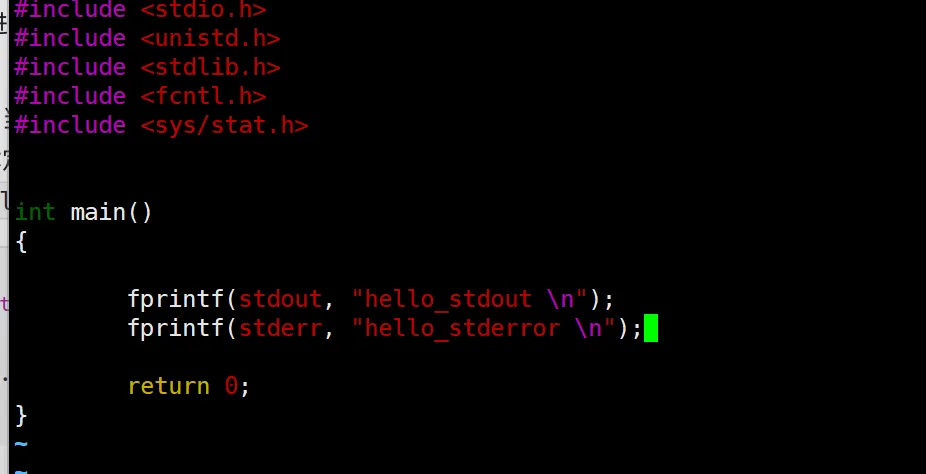

可以看到这样就可以把 stdout 和 这个 stderr 重定向到两个文件里面。
所以,为什么既要有标准输入和标准错误,还有输出的时候用到 printf 或者 perror ,cout 和 这个 cerr。 其实主要是为了方便我们查看这个常规消息和错误信息,毕竟我们可以使用重定向把他们重定向到两个文件里面。方便我们以后日志的型形成。
那如果我们把标准输入和标准输出打到同一个文件里面呢,还是按上面那样重定向可以吗?

很明显是不行的,其中一个被盖住了,主要是因为 > 我们之前讲是清空写,所以,我们其中一种方法就是用这个追加重定向。
还有一种常见做法是什么呢?

就是这样, 1 先重定向到这个文件,然后 2 重定向到 &1 。看着奇怪,但其实是 shell 的一个语法。原理和重定向的一样,1 重定向到新文件不就是把新文件在文件描述符数组的内容拷贝到 1 ,这里就是 把 1 这个地方的内容拷贝到 2 。
1.3 看看源码
之前讲了那么多,现在呢我们来看看 linux内核里面是什么对这个文件来操作的

打开 2.6.18 的内核呢,找到这个 task_struct ,里面就可以找到我们之前提到的文件描述符表的指针,就是这个 struct files_struct *files 。
转到定义,可以看到:
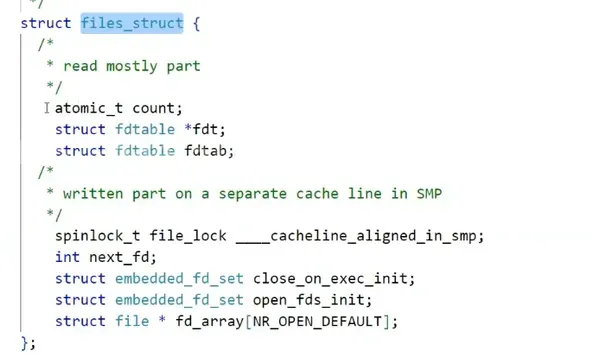
可以看到第一个参数就是这个 atomic_t count 的引用计数。再看最后一个 strcut file * fd_array 这个就是之前提到的指针数组,文件描述符是它的下标。可以看到文件描述符表里面除了这个指针数组之外呢,还有别信息。
可以看到这个数组的大小是一个宏,默认是 32 或者 64 . 这个大小是可以变的,最大可以到 65535 .后期讲到线程再谈.
然后在转到这个 struct file 的定义,这个就是之前提到的代表打开的文件,的结构体:
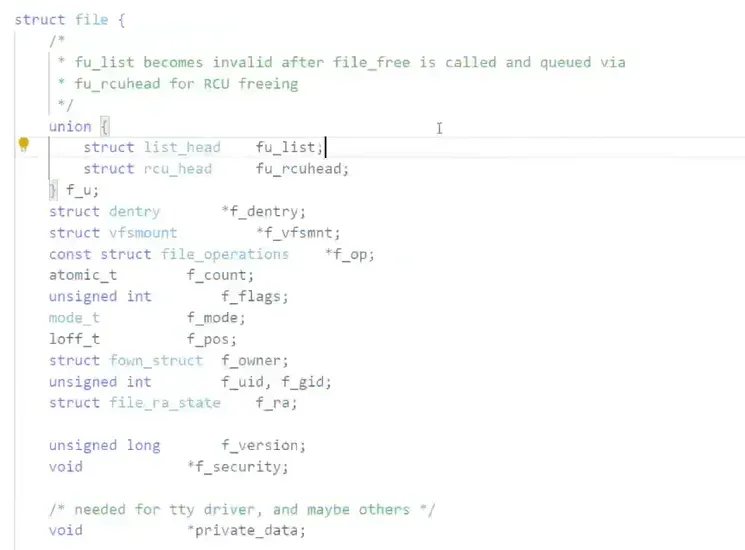
可以看到,着里面有之前提到过的 f_count 引用计数, f_flags 文件打开的方式 ,读打开还是写打开,还是清空或者追加之类的. 还有 f_mode 文件的权限之类的.
还有这个 f_pos 这个就是我们操作文件的时候,光标的位置.我们打开的文件的内容是一个一维数组,把抽象的文件给他具象化成一个数组.而且是 char 类型的,这个 f_pos 就是这个数组的下标.而且这个值只有一个.
所以,我们就理解了只有这个pos到什么位置,我们才能操作什么位置.比如说我们刚写完的内容,我们马上就要读上来,是都不上来的,光标必须移到开头.所以,我们很少用读写打开.当然后面也用得到.
我们继续看可以看到还有一个这个联合体 union 里面放着就是这个 struct file 穿起来的列表,这个是有相关算法的,暂时不表,主要是见一下.
文件管理有文件管理自己的链表,进程管理也有进程自己的链表,所以文件和进程管理是解耦的.这样也方便操作系统去管理.
PCB可以通过这个文件描述符表来找到相应的文件,这样就可以联通起来,并且不影响这个解耦的特点.
之前提到过,这个struct file里面关联着这个文件的内核级缓冲区,再这里面也能找到
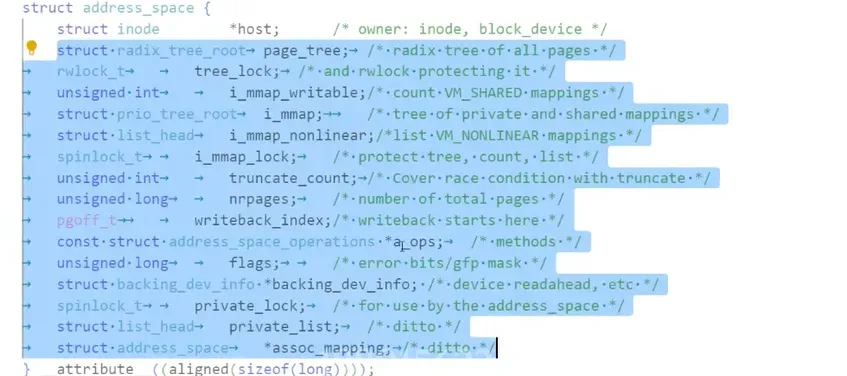
就是这个 struct address . 这个就涉及到后面的一些知识这里只是简单一说. 操作系统管理内存其实不是就是直接一大块管理的,而是把内存分成小的内存块 大小 4KB , 去管理的. 这个 4KB 的小块叫内存片. 那么操作系统怎么管理这个内存片呢? 先描述,再组织. 这个内存片被串起来放在一个链表叫 struct page 里面,这个就叫内存片.
我们之前也提到过,C语言里面是可以实现把同一个结构体放在不同的这个数据结构里面的. 一个 struct file管理自己的缓冲区,只需要管理自己的内存块就好了.
但是,细心的同学可能发现,这个 struct file 里面好像并没有存我们之前提到过的文件的权限,修改时间,属性之类的.
确实是这样的,文件的这些硬属性其实是放在另外一个结构里面叫 inode, 通过这个 struct file 可以找到这个 inode.
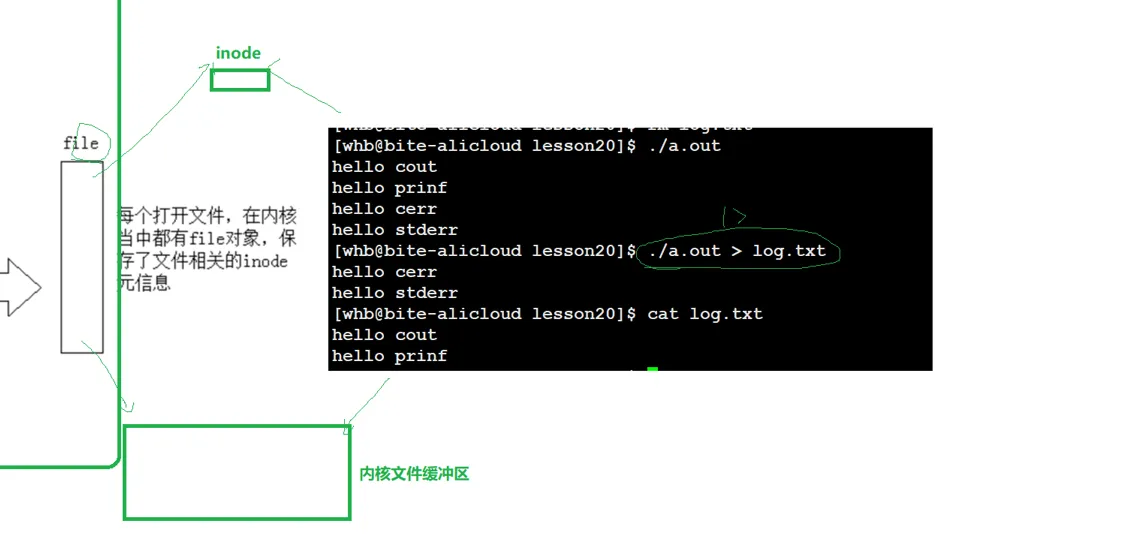
所以,一个磁盘里面的文件被打开,就应该是这样的。
2. 理解一切皆文件
我们之前经常说的 linux 一切皆文件。比方说 windows 下是文件的,在 linux 下也是文件,在 windows 下不是文件的,比如说键盘,显示器,网卡之类的硬件也被抽象成了文件,我们可以用访问文件的方法来访问他们,获得信息。甚至其实管道,套接字这样的东西也可以看成是文件,接口也是文件接口。
首先,这样做的好处就是开发者只需要一套工具或者API就可以调取linux中绝大部分资源,比如写文件,不管是往什么东西里面写,都可以用 write ,因为一切皆文件。
那么,这个是怎么做到把这些硬件什么的,也看成是文件的呢?
首先,我们之前说过一个层状结构,底层是硬件,硬件往上一个就是驱动,相当于导员。再往上就是操作系统。所以,OS不直接和硬件打交道,要通过驱动来和硬件打交道,这些都是我们之前提到过的。
操作系统可以通过打开文件给硬件发送一些协议字段来操作硬件,打开磁盘之类的。后期我们在谈.
思考一下,不同的硬件是不是有不同的读写方式的接口,键盘有键盘的读入方式,显示器有显示器的读入方式,网卡有网卡读入方式,这些硬件都必须支持读写,但是他们的读写方式,一定是不一样的。
还有,操作系统既然要管理这些硬件,就要拿到这些硬件的信息,比如说设备的状态之类的,拿到这些信息的方式不同,因为是不同的硬件,但是必须要有。 这些为后面打个铺垫。
我们知道操作系统要管理硬件,怎么管理,先描述再组织,所以,内存里面一定有每一个硬件的描述结构假设叫 struct device 吧,这个结构体就包含这个硬件的信息比如说这个硬件是什么啊,他的状态是什么啊之类的。
还有一个非常重要的点,我们之前说不同的硬件有不同的操作方式,但是都要有这些操作方式,所以这个 struct device 里面,一定要有能够找到各自对应的硬件的操作方式,
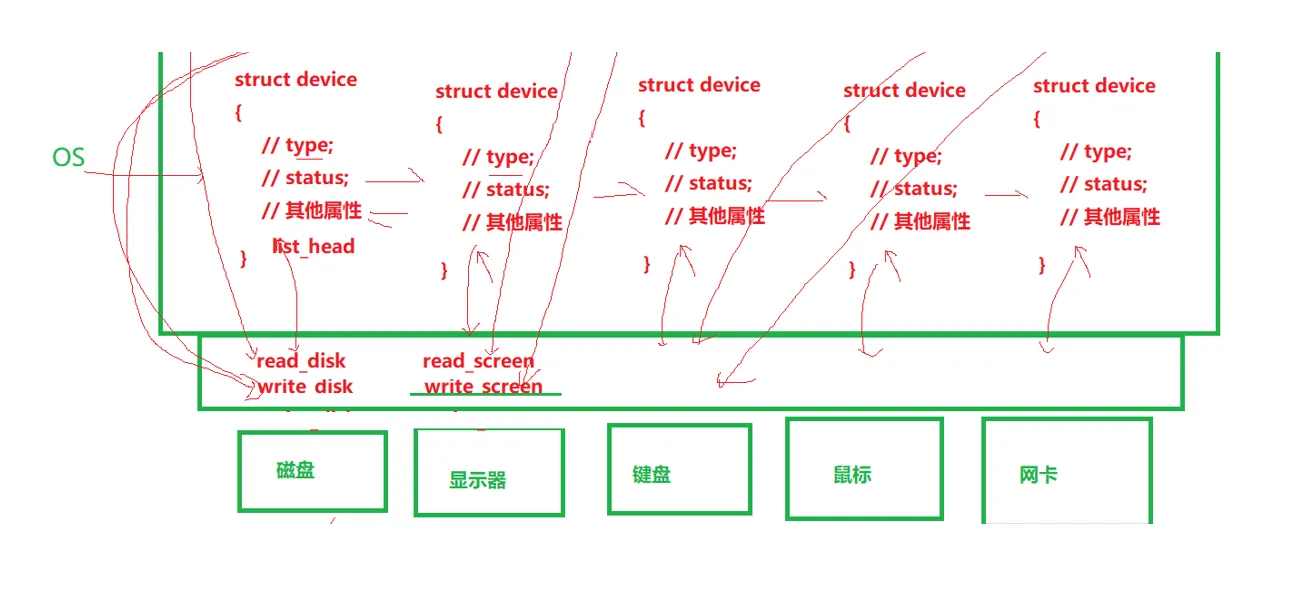
然后把这些结构体串成一个链表之类的数据结构让操作系统管理起来。操作系统想要管理对应的设备或者拿到对应的信息就可以直接通过对应的结构体拿到信息和操作方式,比如图中的读写方式。
当然,这个机器启动的同时磁盘也启动,也是操作系统的一种设备管理
当我们用户想要访问这些设备的时候,比如说往显示器上打字,
对应的进程就要通过他的pcb,找到文集描述符表,然后再找到对应struct file,这个 struct 里面有这个文件的属性,缓冲区,这是我们之前说的。
再补充一个,这个struct file里面应该还有对应文件的操作方法,但是,我们知道 C 语言的结构体里面不能和类一样定义函数对象。但是,可以放函数指针啊:
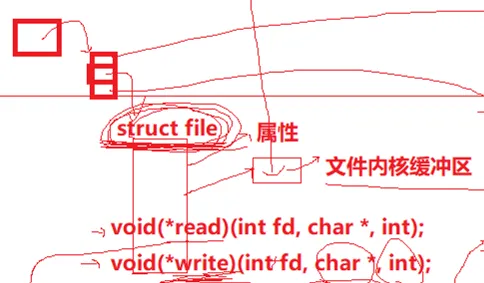
可以看到,假设这个里面有这个 void(* read)(int fd. char* int); 的读的函数指针,和写的函数指针等等。
我们之前说过,硬件也要有各自读写操作的同实现方式,只要我们把这些操作的函数的类型同一,内部怎么实现的我不管,只要这些接口的类型统一了,不久可以通过这个 struct file 里面的文件指向任意一个操作了吗?
指向任意一个操作意味着什么?意味着可以通过这个文件来访问任何的设备。 所以, 我们可以得出结论,访问设备,都是通过函数指针指向的方法进行访问的!函数指针的类型名,参数,都一样!
感受一样,这样一个动态的,通过 调用的函数指针都是相同的,函数指针指向的不同的这种方式来实现多种设备的调用,这不就是 C语言版本的多态吗?
多态不叫抄袭,当一个特性在很多语言里面都有的话,这个其实就是整个计算机世界里面的一个性质了,因为用的很多嘛。
这里是用了函数指针来实现的多态调用。 C++ 里面呢?父类和子类里面不都是有虚函数表指针的?虚函数表,不也是函数指针吗?
所以,通过这样多态调用,就可以屏蔽底层的硬件差异,全部通过这个文件层调用相同的接口来实现对不同的设备的操作。
我们说谁来打开文件,操作文件,是进程,进程接触得到这些硬件吗?不会,进程只会通过这个 struct file 里面的这些文件指针来进行对应的操作。进程知道他操作的是硬件吗?进程不知道, 进成只知道他在操作这个 struct file ,在操作这个打开的文件。此时,我们就骗过了进程,让进程以为,进程一直在操作文件。
骗过进程就是骗过谁?骗过进程就是骗过用户,用户操作文件,或者用户访问硬件实际上都是进程去访问。所以,用户就以为一切皆文件。 所以,这就是为什么 linux 下,一切皆文件。
简单来说就是通过一次多态调用,屏蔽掉底层硬件的差异,让进程以为他一直在操作文件,骗过进程,就是骗过用户,所以 linux 下 ,一切皆文件。
这个 struct file 往上,我们叫虚拟文件系统 VPS。
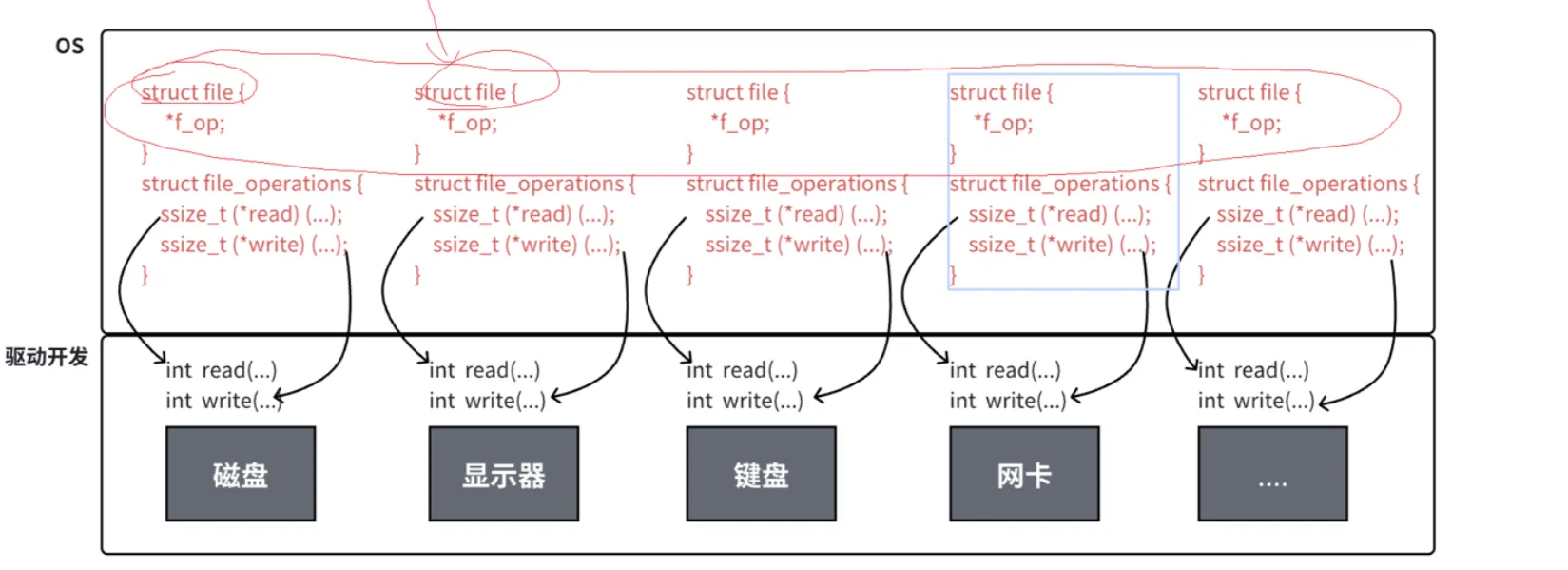
软件工程里面有一句话是计算机世界里面的一切问题都可以通过一个新增一个软件层来解决,而这里就是这个道理,新增了这里的 struct file 这个软件层,通过多态来屏蔽底层接口的差异,新增软件层越往上越抽象,就像多态调用最抽象的就是最上面的基类,这里的基类就是这个 struct file
接下来呢,我们在源码里面见一下,这个“一切皆文件“ 是怎么实现的:
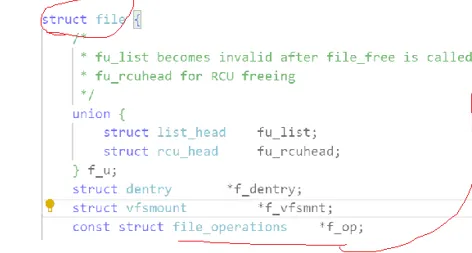
可以看到这个这个文件的 struct file 的时候,看到里面有一个结构体叫 const struct file_operations
这个就是这个刚才提到的,在这个 struct file 里面的找到操作方法的一个指针,因为这个操作方法有很多,所以操作方法单独封装到了一个结构体里面,通过这个指针找到:

3. 文件缓冲区
3.11 什么是文件缓冲区
我们之前也提到过缓冲区的概念,对文件的任何操作都要先经过缓冲区,所以,我们大体可以感知到缓冲区其实就是内存里面的一段空间。
3.2 为什么要引入文件缓冲区
为什么要引入缓冲区呢?打个比方,假设我网购了一个杯子,没有特殊说明的话,快递小哥是会送到这个菜鸟驿站之类的,然后我再去菜鸟驿站拿到,这是一个很正常的拿取快递的过程。如果没有这个菜鸟驿站会怎么样?假设这个小区里面的人都买快递,快递小哥挨家挨户地送,累都累死了,这样这个小哥的送快递效率是不是严重降低啊?
以前小哥送到驿站以后就甩手掌柜了,咱们自己拿。所以,这个菜鸟驿站的作用,其实就是可以增加效率。小哥就是操作系统,咱们就是用户,缓冲区就是这个菜鸟驿站。所以,缓冲区的引入主要就是增加效率。
但是,我们之前有一个现象,再讲这个文件描述符的时候,说往显示器上打印的时候,没敢把这个文件关掉,这里重现一下:
我们知道这个

是系统调用。而我们平时用的什么 fprintf fputs fputc 之类的,全都是 C 语言里面提供的库函数,他们底层都封装了这个 write 函数:
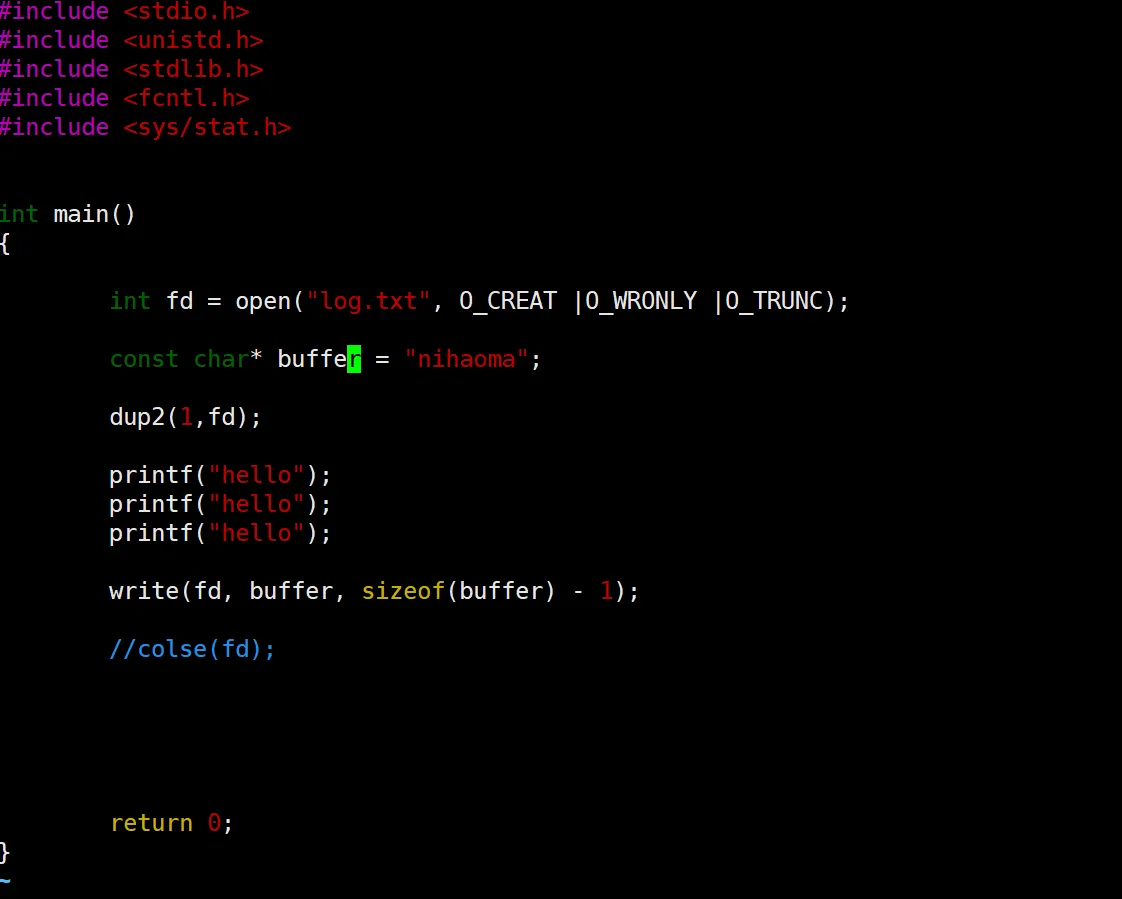
来看这段代码,如果不放出最后一句来的话,大家肯定都能知道会把这些hello 和这个nihao 给打印到这个log.txt 里面去了。但是,如果加上这个 close ,就不一样了:

可以看到这里是只输出了你好啊,(ps:我又忘记敲回车了,有点黏糊,不影响,嘻嘻).
而且,细心的同学或许会发现,如果我们把这个 close注释掉,我们打印出来的结果其实是这个 nihao 在前,这个 hello 在后的,因为这个 write 是系统调用,所以快一点,额,能理解,但是抽象。
3.3 理解文件缓冲区
上述这些现象是为什么呢?种种迹象表明,我们的缓冲区,不止一个!! 事实也确实如此。下面我们就来详细介绍一下,文件缓冲区:(以写缓冲区为例)
首先,我们说,文件被打开,struct file 被加载到内核里面,磁盘里面的文件和这个 struct file 之间有一个缓冲区,这就是第一个缓冲区,文件内核级缓冲区,这个缓冲区在内核里面。
而我们常说的printf \n 什么行刷新之类的,是C语言给我们提供的缓冲区,这是第二个缓冲区,用户级的语言级的缓冲区。
有同学可能会对这个困惑?语言为什么可以提供缓冲区,这个缓冲区应该放到哪里?
还记得这个 FILE 结构体吗?我们之前说,他封装了这个文件描述符 fd ,这个就是 C语言提供给我们的文件的表示,语言层的缓冲区其实也被一起封装在了这个 FILE 里面,比如 stdout 不就是一个语言级缓冲区吗?
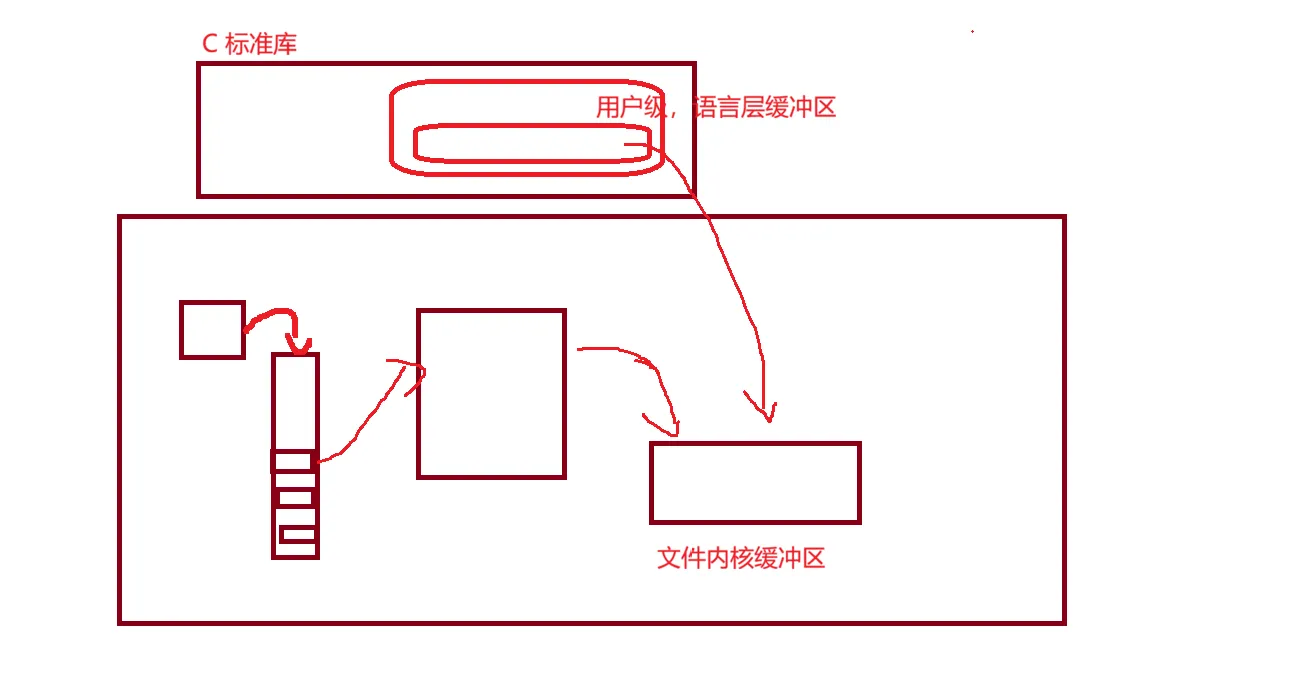
大体结构就是一个这样子的。 C语言库提供的缓冲区呢,只有被刷新到这个文件内核级缓冲区里面,才可以最后被操作系统刷新文件内核级缓冲区的时候,刷新到文件里面。
所以,这个就可以解释为什么write写的东西出现在最前面,而且这个如果printf以后,之恶close(fd)会打印不出来,因为只是在这个用户级,文件缓冲区里面了,并没有到这个文件内核级缓冲区。
为什么之前fclose关闭文件就可以呢?别忘了这个 fclose 也是库函数,里面出来封装了 close 这个系统调用,还封装了一些别的逻辑在里面,其中就包括这个语言层缓冲区。
那么,为什么要有两个缓冲区呢?操作系统有内核缓冲区了,为什么这个C语言库还要再提供一个缓冲区呢?
很简单,答案还是要提高效率。如何提高?
我们之前说的,我们C语言库里面写函数都封装了write,而write是系统调用,系统调用就要有时间和效率上的花费,所以,比起用户输入一个系统调用一次,还是等到比方说用户写了十个字符再调用一次,这样就减少系统调用次数,也是提升效率。
说到这里呢,还有一个问题没有解决,用户级缓冲区刷新方式有三种:
第一种立即刷新,也就是无缓冲,也叫写透模式(WT),故名思意就是不刷新。这个很少我们用得到,后期细说。
第二种就是最常见的满刷新,也叫全缓冲,等到缓冲区满了以后再一次全部刷新到内核缓冲区里面,这个效率最高,普通文件采用的就是这种方式。
第三种就是行刷新,也叫行缓冲,我们之前提到过 \n 立即刷新缓冲区的行缓冲就是这个。为什么要有这个呢,主要是为了方便是人来看,思考一下如果我们看文件,是原因看黏黏糊糊一大坨好一些,还是一行一行的看?我选后者。这个行刷新呢主要使用的是显示器一类。
我们在打算法竞赛的时候,使用C++的时候,也会遇到缓冲区的问题,一个是 cin.sync_without_stdio(0), 这个是解绑
C 和 C++ 的缓冲区,因为C++ 要兼容C 语言,所以他们的缓冲区套一起的,C++ 在刷新自己缓冲区的时候,也要刷C语言的。还有一个就是 cin.tie(0) 好像是这么写来着,这个是解绑 cin 之前要先刷新一次的缓冲区的。之前都有提到过,这里不细说。
刚才我们一直说刷新缓冲区,什么叫刷新缓冲区?怎么刷新,其实就是拷贝。 数据由 C语言缓冲区根据这个 fd 刷新到这个文件内核缓冲区,相当于是数据交给操作系统,操作系统刷新缓冲区,相当于是吧数据交给硬件,这些过程本质都是拷贝。
总结一句话,计算机数据流动的本质就是 : 一切皆拷贝。
这里再补充一点奥,这个内核级缓冲区怎么刷新呢?这个就是由操作系统自己来决定了,反正他写透或者全缓冲,行缓冲肯定都有,还有一些更加复杂的情况。 注意,我们只需要把数据给操作系统,就可以看成是把数据给硬件了。 就想发快递,只要给了驿站,就可以看成是对面一定会收到。
3.4 见见缓冲区
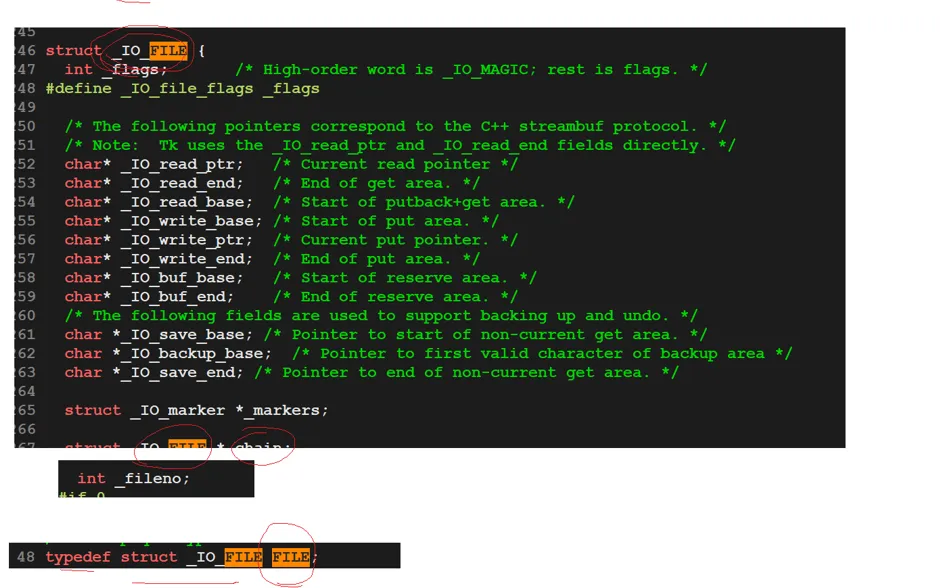
可以看到这个就是 FILE结构体被定义的样子,FILE其实是被 typedef 类型重定义了一下,上面的 IO_FILE 里面有这个 _fileno 文件标识符。还有各种缓冲区定义。
当然这里注意,缓冲区是分读缓冲区和这个写缓冲区的,两个缓冲区都分,我们上述例子是以写缓冲区为例子的。







