
Linux 系统编程 文件篇 (四) 文件系统
[TOC]
Linux 系统编程 文件篇(四) 文件系统
1. 简单回顾
在学习文件系统前呢,我们先来回顾一下我们之前在讲 linux 的时候谈到的有关文件的一些设计和概念。我们之前说的文件都是内存级的文件,也就是被操作系统打开的文件是如何处理的。 文件打开后呢,会有一个 struct file 加载到操作系统内核里面, struct file 链接起来形成一张链表,操作系统对文件的操作转变为对这个链表的增删查改, 这是我们之前谈到的先描述,在组织。
那谁让操作系统打开文件?肯定是用户让操作系统打开文件, 但真正去完成这个让的操作的是谁? 是进程,换句话说,进程就代表的是用户。 所以,了解文件的修改之类的本质就是要了解进程和文件之前的关系。
我们之前还讲到过缓冲区的概念,我们说每一个打开的文件都有一个自己的内核级缓冲区,通过自己的 struct file 可以找到。 对文件进行读写必须先把数据加载到缓冲区。 这个加载到内核级缓冲区的过程其实就是操作系统把数据从用户层 拷贝到 内核级缓冲区。 数据流动的本质,其实就是拷贝。
为什么是拷贝?是由冯诺依曼体系结构来确定的。 数据必须加载到内存,cpu才可以进行访问和运算。这就是拷贝过程。 所以,我们经常说的增加效率,有什么加快读写啊,扩大内存之类的其实就是增加这里拷贝的效率。
说起缓冲区呢,刚才我们笼统地称为用户层,其实我们也知道缓冲区其实有两个,一个是C语言提供的缓冲区,一个是操作系统内核级缓冲区。 为什么要提供两个缓冲区是为了减少系统调用,系统调用就要有消耗,消耗在哪里我们后面说,所以,这里也是一种增加效率的设计。 以前写一次调一次,现在写一包调一次系统调用, 拷贝用户级缓冲区到内核级缓冲区。 那操作系统是怎么把数据拷贝过去的呢?
这里就要提起我们之前用到的文件描述符了。 我们之前说指向struct file 的指针会放在一张表叫文件描述符表里面的一个数组里面。 数组下标就叫文件描述符。我们使用系统调用都是用到文件描述符。这里也就说明我们之前使用的语言层的文件接口,比如 printf fprintf 之类的,底层都封装了文件描述符。 这也是这个语言和操作系统的一个关联。比如C语言里面打开文件方式,就是open的一些选项按位或在一起的。 这也解释了用户级缓冲区放在哪里,放在FILE* 的对象里面嘛, 封装起来了。
当然,有了这个文件描述符呢,我们又可以做到重定向, 先关闭再打开,或者调用dup2, 狸猫换太子,这里就不多赘述了。
再说会到缓冲区, 用户级缓冲区有三种刷新规则, 首先就是不刷,写透模式; 然后是全刷新,写满缓冲区再刷; 最后是行刷新,一行刷新一次。注意,这里的刷新指的是用户级缓冲区刷新到内核级缓冲区里面。 对于写文件来说呢,主要用的就是全刷新,如果想要立即刷新可以调用 fflush() 这个库函数, 要特别注意的一点是,\n 的行刷新特性对写文件来说是不起作用的。
行刷新嘛,顾名思义就是写一行刷新一次,主要是显示器,等设备使用,符合我们人类的阅读习惯,方便人来看的。 这里 \n 就可以实现行刷新, 当然 fflush() 也完全没有问题。
内核级缓冲区的刷新方式对比用户级的刷新方式复杂程有过之而无不及,但是我们不需要操心,操作系统会根据情况自己选择刷新方式。 那我们能不能也操控一下呢?当然可以, 有一个系统调用的接口叫 fsync 就可以实现,后期我们再说。
缓冲区的引入,就是为了减少系统调用,也可以减少一下不必要的用户切换和权限的问题,后期我们会讲。总是就是增加效率。 其实再用户层面也有意义, 比如使用 printf 进行格式化输出的时候,我们调用 printf 传入的数字或者字符让他格式后的时候,他格式化之前的数据或者格式化完毕的数字就存在这个缓冲区里面。 方便实现这里的格式化输入输出,也是缓冲区引入的一个语言层的意义。
再来呢我们自己写了一个 glibc 的文件处理部分 , myfopen myfclose 之类的接口。 这里呢我们也知道了编译器是会对我们自己写的程序动手脚的,比如刷一下缓冲区。 我们自己调 myfclose 要刷新一下缓冲区,这也是为什么我们打开一个文件之后要关闭一下。
但是我们在这里简单实现的时候,采用的方式是 .c 实现 .h 声明的方式。 但是我们注意到,我们日常在写 C 程序的时候,系统并没有提供这里的 .c 源代码,只有 .h 的头文件,和这里的 liib64 目录下的 glibc.so 的动态库,通过这两个东西我们就可以使用这些库函数等接口,所以,我们编译的时候也可以实现一下。具体的后面讲动态库的时候说。
在完成了这个简单的模拟实现以后。我们又演示了这个缓冲区刷新的机制。我们让这个程序打印数据,但是不刷新语言级缓冲区,打印的时候打印一下缓冲区,再开一个shell窗口,监视一下这个被写的文件,可以看到里面是没有东西的,当我们刷新缓冲区的时候,文件里面才会有。
但是其实这里还是有运气成分的,因为这个操作系统的内核级缓冲区我们说是操作系统自己控制的,合适了就刷,所以,我们能观察到也是有些运气成分在里面,
如果我们想要操作系统立即刷的话,就用到了我们之前说的 fsync 接口啦:
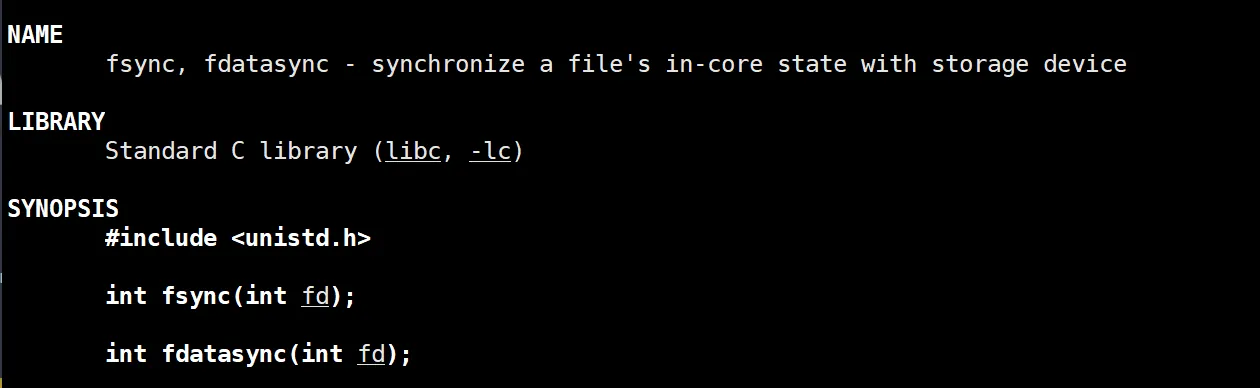
可以看到传 文件描述符过去,操作系统就立即刷他 ,有了这个系统调用呢,用了以后就不受操作系统影响,必须立即刷新。
linux 里面 也有一条指令叫 sync , 意思是同步。 其实也是刷新。 我们在进行各种各样操作的时候会产生一些缓存,用 sync 可以立即把缓存数据刷新到磁盘。
到后期我们学习数据库,说是 mysql redis 等等的时候, 其实数据库都是一个大文件,里面存着数据,它跑起来也是进程, 换句话说,对数据库的增删查改都是在内存里面进行的,进程嘛, 这样修改完了以后都是先进缓冲区,然后再 sync 刷到这个磁盘,或者哦我们说叫 可持续化存储设备, 或者叫落盘。
所以只要我们以后识别出这两个东西的关系是进程和文件,那其实也就妥了,系统层面到底是怎么实现的就不再重要了,因为走的都是我们说过的这一套,文件描述符,缓冲区之类的。
再之前我们也讲过 linux 下一切皆文件,刚才忘了说了,嘿嘿。 翻翻前面的自己复习一下吧。
2. 文件系统的引入
我们之前说过文件 = 内容 + 属性, 这是对于单个文件来说的。 思考一下,我们之前聊的,都是操作系统对打开的文件,或者说加载到内存的文件进行的操作,但是计算机里面可以有很多文件的, 是打开的多一些,还是没打开的多一些, 那肯定是磁盘里面没打开的多一些啦。 我们之前的篇章,讲到的都是打开了的文件,也就是基础IO部分, 在内存。
我们现在在宏观上,所有文件分为两类,一类是打开的,一类的没打开的。 既然我们有这么多没打开的文件,操作系统是如何精准地找到我们没打开的文件中我们要打开的哪一个呢?
没被打开的文件在哪里?在磁盘。没有被打开的文件多多了,如果归类在磁盘里面如何快速找到。这个文件是一定要被找到的,要不然是无法工作的。
这里就涉及到了文件系统的简单引入:
我们知道文件在磁盘里面是目录的结构组织的,树状的有绝对和相对路径可以帮助找到。
文件保存在磁盘上最基本的诉求就是能够被找到。
所以,文件系统也是要完成”找到“这个使命的。 这里就先这么简单理解一下就好,因为涉及到不少东西,我们后面再详细说。
2.1 硬件方面
要真正的理解文件系统,必须要从硬件开始谈。 其实现在笔记本很少用磁盘了,用的都是固态硬盘SSD, 这两个东西的存储原理完全不同。 磁盘现在装个台式或者 更多是服务器后端存储海量数组的时候用得到。 磁盘也是分企业级和用户级或者说叫桌面级的,听名字就知道企业级的肯定更快更大嘛,其实计算机里面不论键盘鼠标什么的,磁盘是唯一的机械设备,也就是外设。
磁盘在功能上也分为什么存储盘, 效率盘, 还有混盘,就是两个都有的等等。 磁盘离CPU更远嘛,所以读写速度上是会慢一些的。 相对也更便宜嘛,比起固态。








