
哈夫曼编码

哈夫曼编码
1.树的带权路径长度:只关心叶子节点的权值,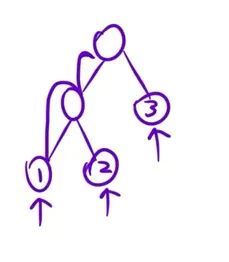
2 * 1 + 2 * 2 + 3 * 1 = 9;
2.哈夫曼树:带权路径长度最小的二叉树,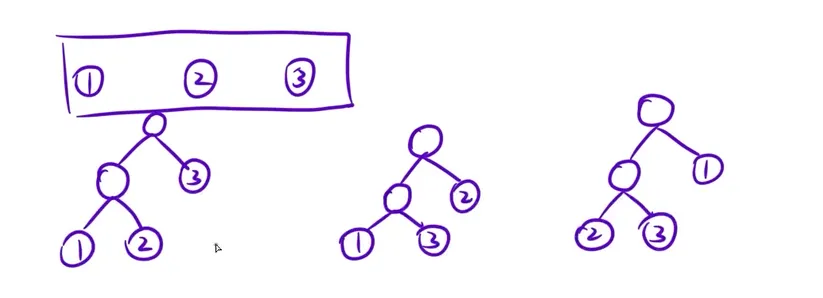
3.哈夫曼算法:构建哈夫曼树,根据贪心策略得到
- 初始化: 把所有叶子节点都看成一棵树

- 贪心:每次选择权值最小的合并新的二叉树(权值小的放地深),新树的根节点再放回去选择
- 重复

4.在构造的过程中就可以计算出带权路径长度,每次合并都把左右子树的权值累加起来,
二 : 证明 : 引理:n个叶子节点,权值最小的,一定在深度最深的地方,并且可以调整成兄弟(先证明引理,反证法)
如果最小的不在最深,可以交换,一定更优。 因为最小的都在最深,所以计算的路径长度都一样,所以可以随便调整
有了引理,就可以每次都挑最小的了
有了引理,再用数学归纳法:先假设一个较小的树成立,再假设 n = k 的时候成立,再证明 n = k + 1 的时候成立。
当 n = k + 1 的时候,可以挑出权值最小的两个合并,然后 n = k 了。我们假设成立。
三:哈夫曼编码
编码的方式有很多,哈夫曼编码是非常有效的数据压缩码
- 统计所有待编码的序列中,每一个字符出现的次数,
- 将次数作为叶子节点,构造哈夫曼树
- 规定左分支为0,右分支为1,那么从根节点走到叶子节点的序列就是该叶子节点对应字符的编码
如何求编码的长度呢? 只需要求带权路径长度的和就好,因为叶子节点代表字符的数量,路径的长度代表编码后一个字符的长度。
通常我们会用到堆,来求最小的权值的叶子节点,注意这里的堆的逻辑和正常是反过来的,堆默认是大根堆,如果要改小堆的话,就要修改一下仿函数,传 greater
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 榆木盖饭的个人空间!
评论