
Linux 系统编程 文件篇 (二) open 函数、权限与文件描述符
[TOC]
Linux 系统编程 文件篇 (二)
1 open 函数介绍
1.1 标记位
上一篇的结尾,我们讲到了我们用的打开文件的库函数其实是封装了,这个 open 的系统调用,然后解释了这个 open 函数的 这个标记位,flags 是一个位图的形式。现在我们继续之前的说。
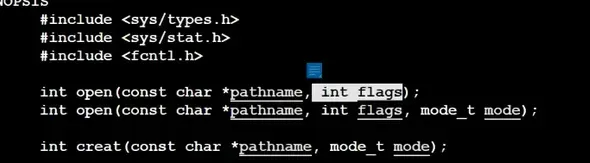
这里补充一下,open 的第一个参数还是指定路径下的文件,绝对路径和相对路径都可以,因为是进程来新建文件,而不是语言层面的。
首先还是从标记位讲起,标记位其实就是宏,man 一下打开可以看到这些标记位都是什么,

这三个我们应该很熟悉,readonly , writeonly , read && write ,分别就是只读,只写和这个读写的形式。
还有几个我们需要认识一下:


第一个是 append 追加,对应就是 ‘a’ ,第二个是 create 故名思意就是创建文件的意思。
第三个其实我们之前也见过,在这个 ‘w’ 打开的时候,我们可以看到这个 ‘w’ 描述:

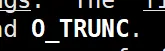
第一个次就是这个 truncate ,清空的意思。
所以,我们就能推断,我们之前说的什么 ‘r’ 打开 ‘w’ 打开 ‘a’ 打开其实就是这些标记位的组合。
比如 ‘w’ -> O_WRONLY | O_CREAT | O_TRUNC , 分别对应 ‘w’ 打开的三个特点,写方式打开,没有这个文件就下新建,每一次都清空。
我们继续看这个 open 函数,说实话有同学可能发现了华点,C 语言里面没有重载,但是为什么有两个同名的 open 函数?其实这里是用宏来实现的,具体的后面会谈。
第二个open函数和第一个一模一样,唯一不同的是,多了一个 mode 参数? 这个 mode 是什么?不卖关子,就是权限。打开的这个文件的权限。其实也不难理解, linux 里面是有权限概念的,如果我新建一个文件去读去写,新建的文件应该是要有权限的,如果我们只是使用第一个 open 去新建,会发现这个权限是乱的。是不符合这个权限的要求的。所以,我们新建我呢教案的时候就可以用第二个 open 去手动设置权限。
1.2 权限
我们之前说过权限是可以看成这个 8 进制数来设置的,所以,这个 mode 的参数类型就给成了一个 int 。
默认就是 0666 ,第一个 0 是用来标志这是 8 进制的。
回归一下权限 首先是对象有 拥有者 所属组 和 other 。 每一个对象有一组权限是 r w x 也就对应 三个二进制位 000.
二进制位为 1 就是有, 为 0 就是没有, 比如 rw- 对应 110 ,八进制下就是 6 。
但是,我们还是会发现,我们新建出来的文件的权限还是不太对,和我们设置的不一样。为什么?
因为有这个权限掩码 umask ,可以手动屏蔽一些个权限。其实这里也侧面说明的这个 umask 也是系统层面的。
如果我们就是想这个新建文件的权限设置的和我们传进去的参数一模一样,我们也可以调用 umask 接口,每错, umask 也是个函数,
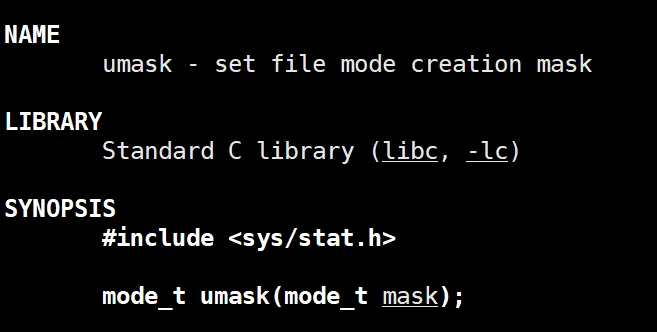
通过我们传入的数据来修改当前程序的一共 umask ,想和传参一样的这个 umask 传参传 0 就好了。
这个umask 是遵循就近原则的,如果当前进程设置了umask ,就按当前进程的来,没有就按系统的来。
1.3 读写接口介绍
还有就是 open 函数的返回值。

可以看到这个值,如果成功打开,返回这个文件的文件描述符 ,这个文件描述符后面有大用,这里先把这个观点抛出来。然后如果打开失败就返回 -1 ,然后设置 errno 。
当我们关闭怎么办?当然也有相应的系统调用,就是close()。
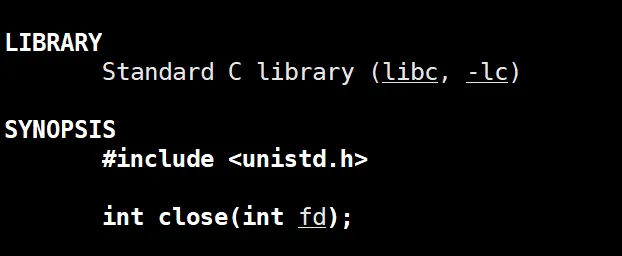
可以看到这里的 close 只需要传入这个文件的文件描述符,也就是 open 函数的返回值就可以关闭这个文件了。
有了开关以后,还要有读写才行,要不然怎么对文件进行操作?
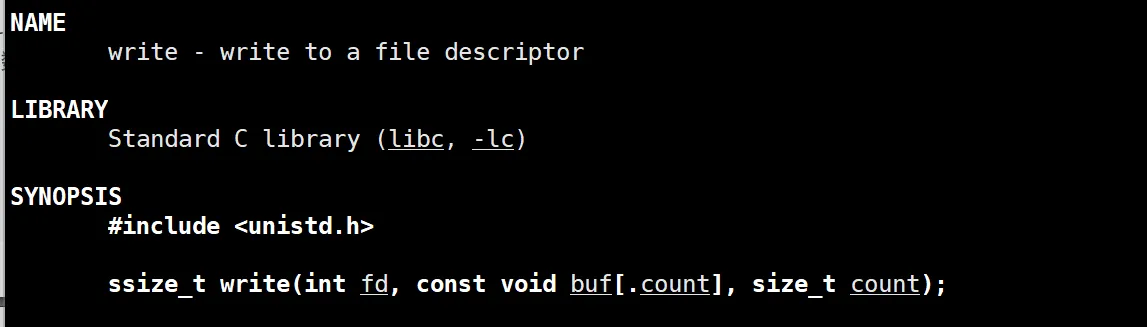
可以看到这里也就这个系统调用,就是这个 write 。第一个参数是文件描述符,表示往那个文件里面写,第二个是要写的内容,第三个是要写的内容的个数。
这里写的方式和我们之前说到的 open 函数的标记位也是是有关系的,open 函数的标志位是什么,这里写的方式就是什么。比如说 如果open 函数里面没有 O_TRUNC 的话,再次写就不会被清空而是从头开始覆盖写。我们语言层面封装的 ‘w’ 和 ‘a’ 其实最后都会转化位系统层面相应的标记位。
我们注意到,这个函数的参数和我们之前提到的 fwirte 的二进制读写传参是很像的。这里我们就又要把这个二进制读写和文本读写再拉出来说说。
我们看到这个 write 的系统调用的要写的内容的地方是 void* 也就是说它什么都能写。也就是说,在系统层面,他时不关心我们是怎么写的,系统什么都能写。所谓的文本写入和这个二进制写入其实都是语言层面的概念。
假如,我要写一个 n = 12345 到显示器上,他是按一万两千三百四十五打印,还是 ‘1’ ,’2’ ,’3’ …. 这样的字符打印。
我们之前也提到过,如果我们用printf是按照字符的方式打印的。如果我们用这个write直接打印这个 n 的话,会发现是乱码,这样其实就是二进制打印的,被这个文本编辑器强行按照这个ascii码给解读成字符了。
如果我们就是像用 write 打印字符串怎么办?我们就需要自己调整格式,先把 12345 转化成字符串,比如用一个 snscanf
,把写好的字符串放在一个 buffer 里面,直接把这个 buffer传给 write 就好了。别忘了系统什么都能打。换句话说,想要系统怎么打印,就看我们对文本怎么解释。我们不解释,库函数有时也会帮我们解释,比如 printf ,fputs 之类,打印就是打印字符串。
那么读文件呢?读文件也好办,有 write 系统调用,就有 read 系统调用:
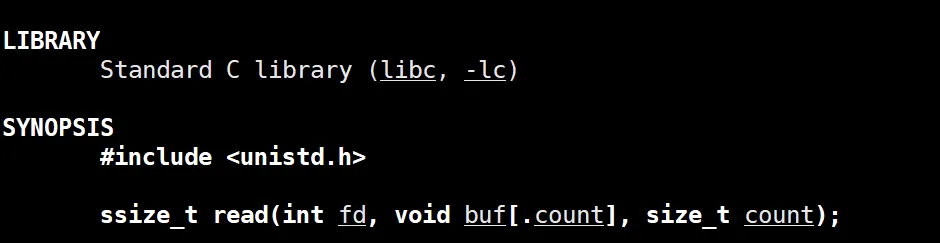

这个read的使用和write大差不差,依旧是系统什么都能读,放到这个 buffer 里面。
这个函数的返回值提一句,如果成功读了,但会读了多少个字节,如果返回零,则表示读到了文件的末尾。读取失败返回小于零的数。或许有同学有疑问,什么时候字符串读,什么时候文本读?其实啊,文件是我们自己的,内容什么的我们其实都知道,什么时候文本读,什么时候二进制读我们自己肯定也知道。
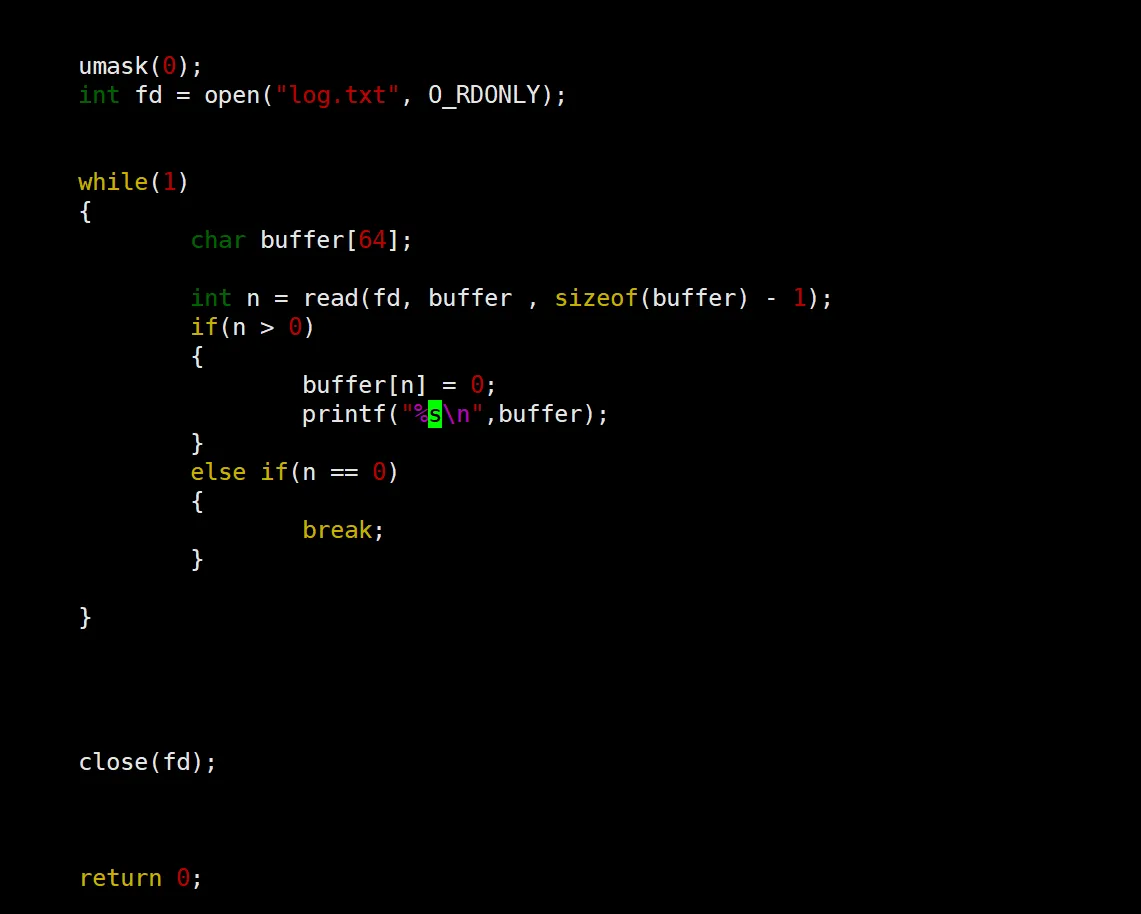

可以看到我们以读方式打开文件的话,其实就不需要传这个权限了,因为不需要新建文件了嘛,所以,这也是为什么open要有两个的原因。可以看到,我们文件里面写的 123456 以字符串的形式就打印出来了,是我们自己手动调整的格式,包括这个char的buffer,还有这个加 \0 的操作。
文件接口其实不止我们以前C语言里面学的那么多,后期我们再谈,但是涉及到输入输出的,其实底层都封装了这个read 和 write,然后再做一些处理,比如帮我们处理格式。
2 文件描述符
2.1 初识文件操作符
我们之前称这个 open 函数的返回值叫文件描述符。我们用到的 write , read ,close 等系统调用,传参都是要求的文件描述符。文件描述符是什么呢?
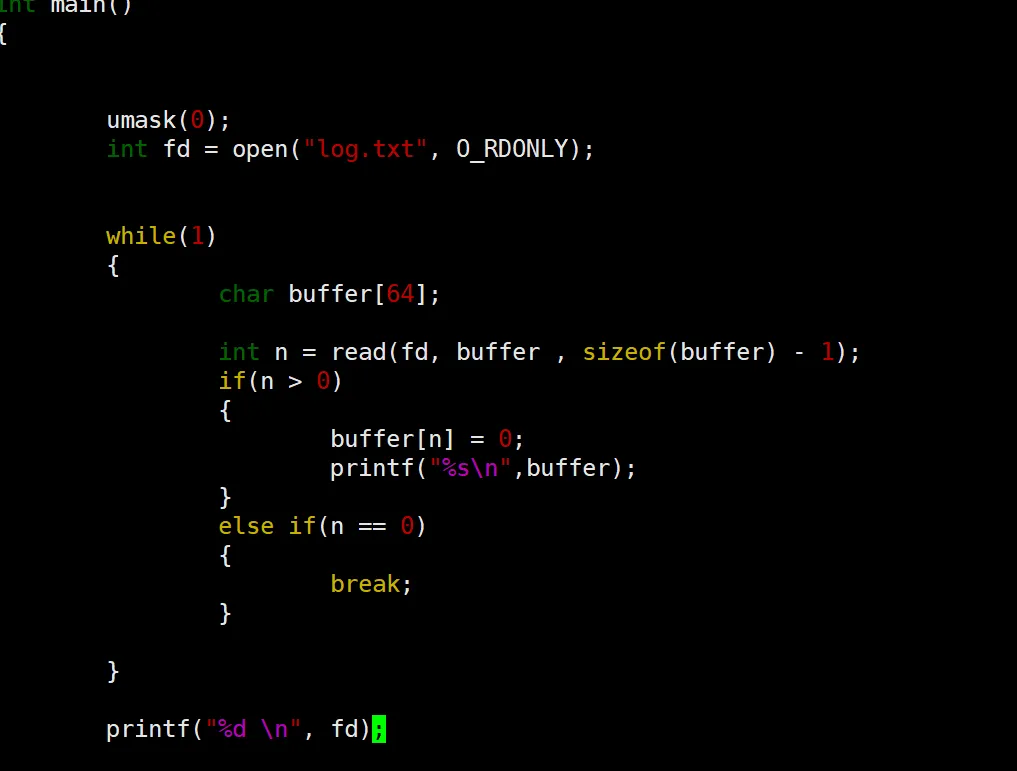

可以看到这个文件描述符,其实就是一个整形数字,表示我们打开的文件。为什么这个数字是从 3 开始的?以及为什么操作系统可以通过一个数字来控制文件的读写和关闭?
我们一个一个来谈:
首先,为什么从 3 开始? 我们说一个进程默认打开三个文件 stdin stdout stderror 而 这个log.txt是我们自己打开的第一个文件,如果 stdin 是第 0 个,那么我们的 log.txt 正好是 3。
所以直接出结论 :0 1 2,其实就是标准输入,标准输出,和标准错误。
我们还观察到,有关文件的系统调用的接口,处理open,因为会自己新建文件,别的接口传入的参数,都是文件标识符。换句话说,操作系统只认 fd 也就是 文件标识符。
但是,这个时候就有同学要问了,我们之前学的fopen,fprintf什么的传入的参数,还有这个 stdin stdout stderror 的类型,都是FILE* 的指针啊。
注意FILE*是语言层面的,是C语言提供的一个结构体,typedef出来的。 typedef XXX{…..}FILE;
但是,实际上我们说打开文件或者往文件写入是进程来做的,文件在磁盘里面要打开必须经过操作系统,,操作系统不相信任何人,所以必须要通过系统调用。所以,我们可以得出结论, FILE*里面一定封装了 文件标识符。
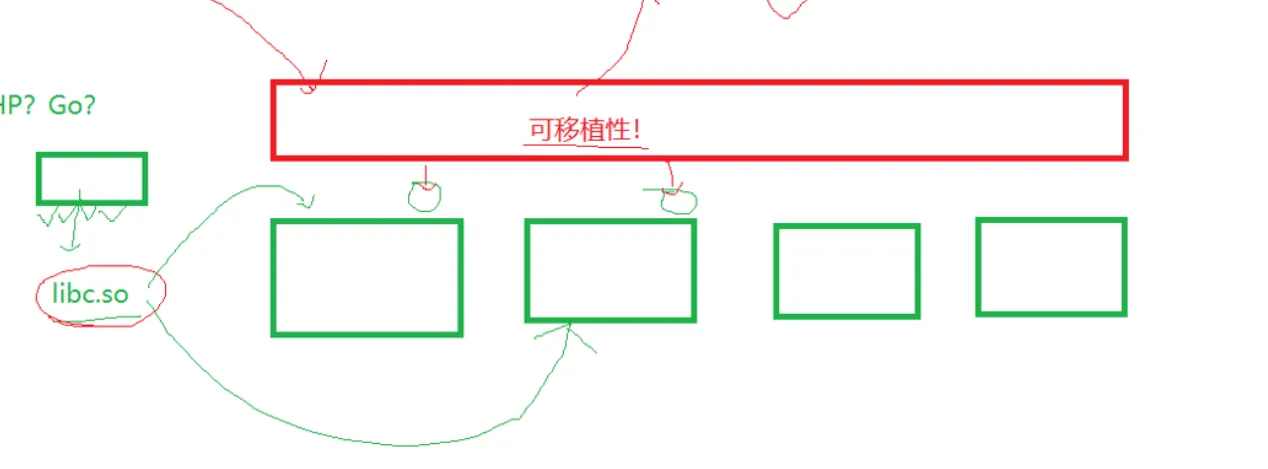
知道了这个封装之后,思考一下,只有C 语言里面有这个封装吗,C++ java python php go 等等,这些语言有没有这样的封装?为什么要有这个封装。
首先第一个问题的答案是肯定的,比方说c++里面有I/O流, cin cout cerr,其它的面对象的语言也都是有的。
为什么要有这个封装,我们思考一下,操作系统不止一款吧,比如说有 windows linux macos等等,这些操作系统是完全一样吗?肯定不是。但是,我们能说一种语言只能在一个操作系统使用吗?比如说C语言只能在linux上使用,别的操作系统使用就报错,肯定是不行的。所以 C语言的库 libc.so 在实现的时候,就必须把这些平台的接口全部实现一份出来,然后再封装一层,使得用户在不同平台下使用的方面上来讲都是一样的。因为库里面有很多平台的实现,在特定的平台需要的只是这一个平台的,其它的就会被裁剪掉,没错还是老朋友条件编译干的。
说了这么多,总结一句话,就是为了增加这个语言的可移植性,让他在那个平台下都能跑。
那么为什么语言要增加可移植性?如果可移植性差了,用的人就少,那这个语言相关的社区,生态就少,久而久之这个语言就被挤占没了淘汰掉了。所以,增加可移植性,是让更多的人去使用,增加市场的占有率。
2.2 再探文件表示符
刚才我们只回答了第一个问题,为什么我们自己开文件是从 3 开始的。
现在我们来回答第二个问题,文件表示符是什么,为什么操作系统可以通过文件标识符来对文件进行操作。
文件标识符的 fd 从 0 开始。是不是很熟悉,数组下标也是从 0 开始的。所以,文件标识符会不会是一个数组下标呢?
其实,文件标识符还真是数组下标。
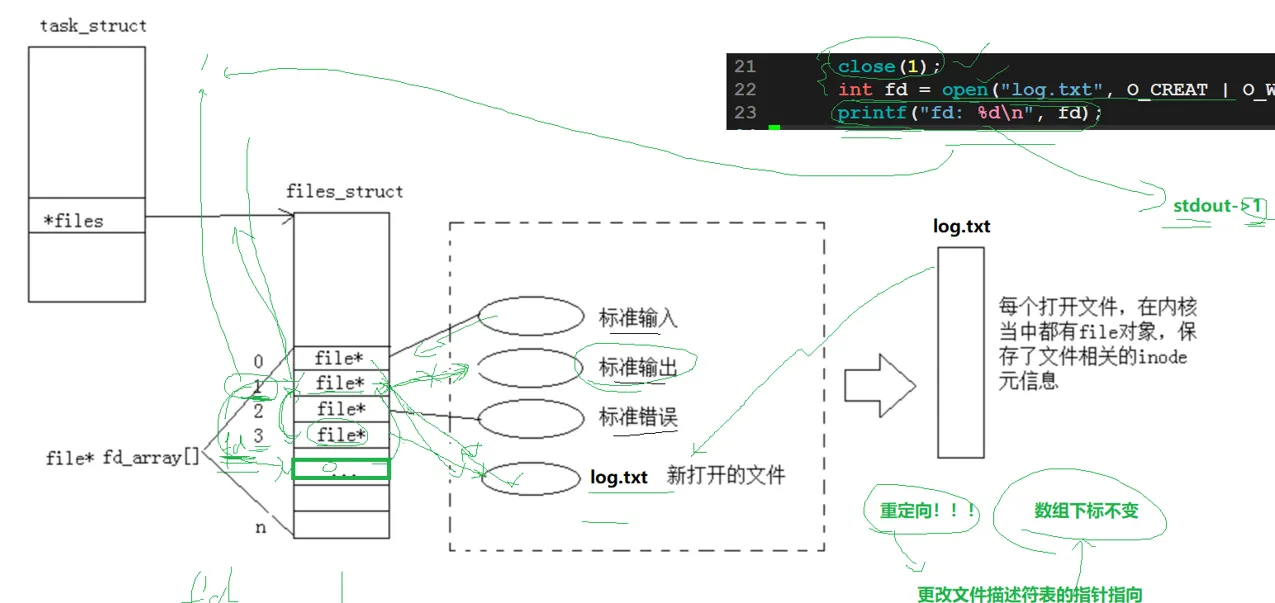
在文件篇一里面,我们提到,进程可以打开多个文件,进程一定是要对文件进行管理的,怎么管理?先描述,再组织。
比如说一个磁盘里面的文件被打开了以后,就会有 struct file 被加载到内存,这个 struct file 就是用来描述这个文件的。换句话说,struct file 就代表被打开的文件。而在这个 struct file 和这个文件之间,还有一个内核缓冲区的存在,数据只有先经过缓冲区,才能在两边流动。
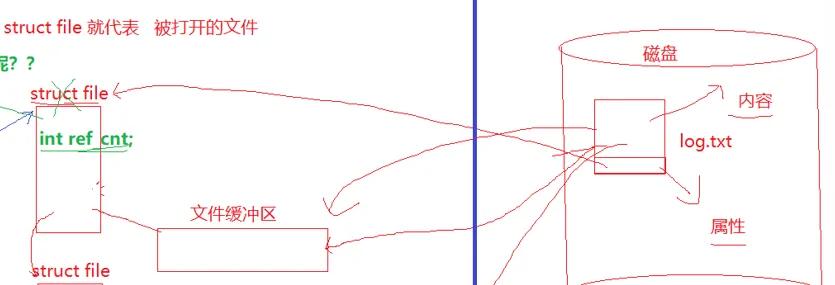

这个 struct file就是我们继 task_struct ,mm_struct ,之后学到的第三个内核数据结构的结构体节点。知道了这个 struct file以后,之后肯定就是要再组织了,依旧是串成一张表。
和之前有所不同的是,文件描述符表 struct files_struct 里面还有一些其它的信息,存储这些 struct file 的地址的是这个文件描述符表里面的一个指针数组 struct file* fd_array[]
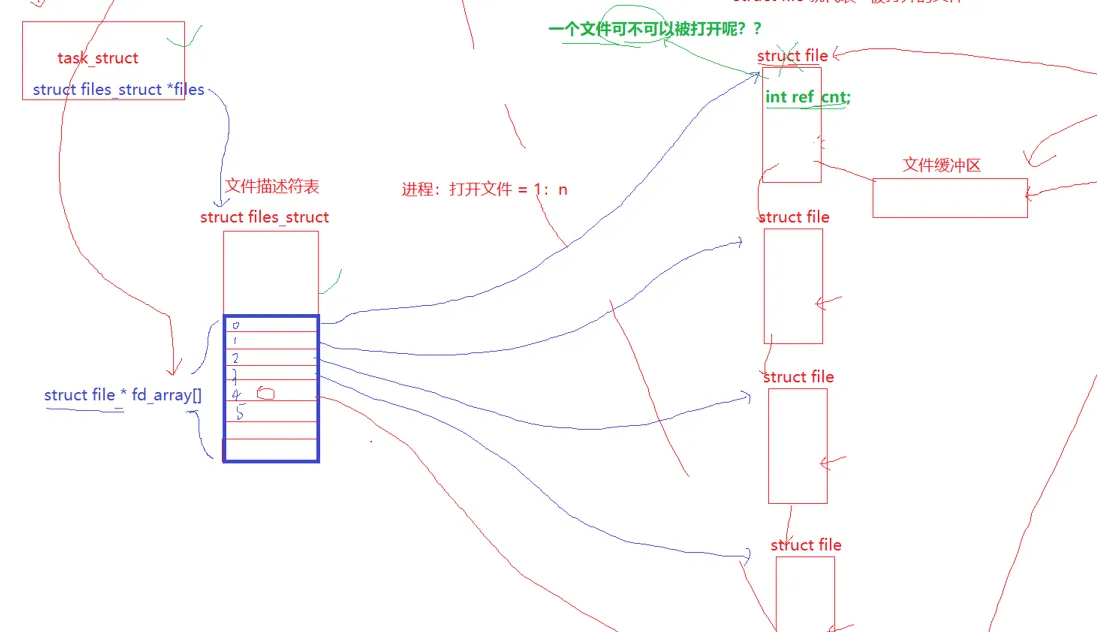
进程的 pcb里面只要找到这个文件描述符表,就可以把这些打开的文件管理起来。
而我们刚才说到的文件描述符 fd 就是这个 struct file* fd_array[], 的指针数组的下标。数组里面存储的是每一个struct file的地址。
至于这个文件缓冲区,对文件进行任何操作,都要把文件加载到内核对应的文件缓冲区内,打开文件的时候也会预加载一些,方便读。本质就是 磁盘到内存的一个拷贝。关于缓冲区更多的内容我们之后会详细说,这里先知道有这么个东西就好。
我们再使用像 read 等系统调用的时候,传入这个 fd ,通过当前进程的 PCB 找到文件描述符表,然后访问这个指针数组对应的下标,就可以找到这个struct file,即这个被打开的文件,然后从缓冲区里面拷贝内容出来,放到我们要放的地方去。
所以,read 本质上是内核到用户空间的拷贝函数。
3. 重定向原理
3.1 重定向原理初步
我们之前也见识过重定向,也知道输出重定向是 w 写,追加重定向是 a 写。那么重定向的原理是什么呢?
我们知道,程序与运行默认打开三个参数,stdin stdout stderror,分别对应键盘文件,显示器文件,显示器文件。
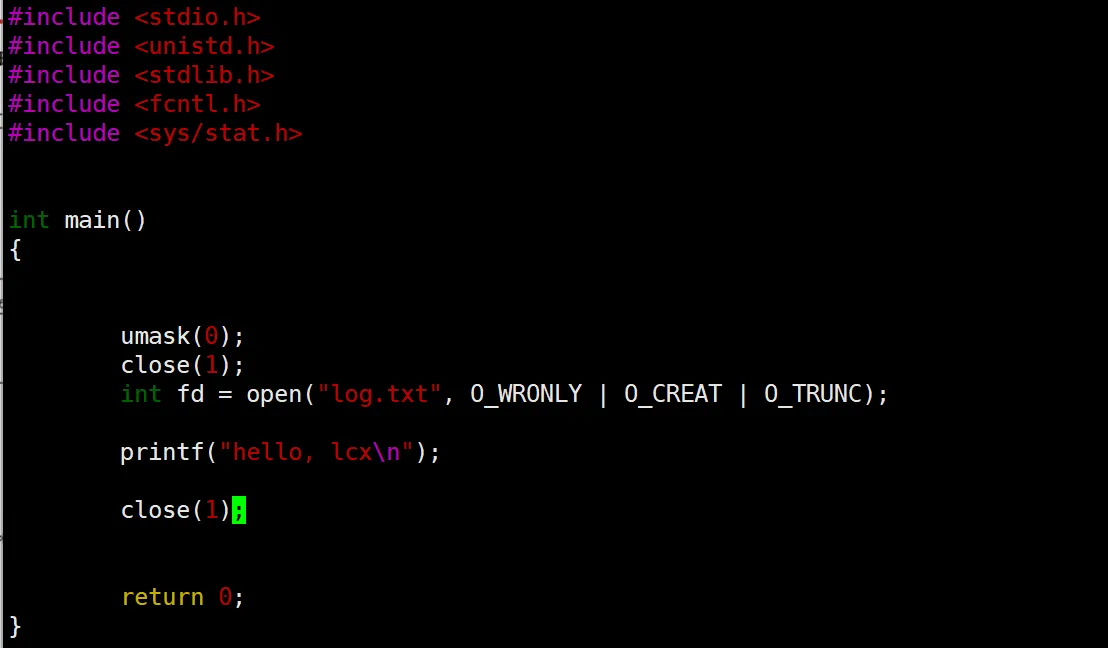
如果我们把这个 stdout 给他关了,再打开一个别的文件,然后 printf 会发生什么呢?
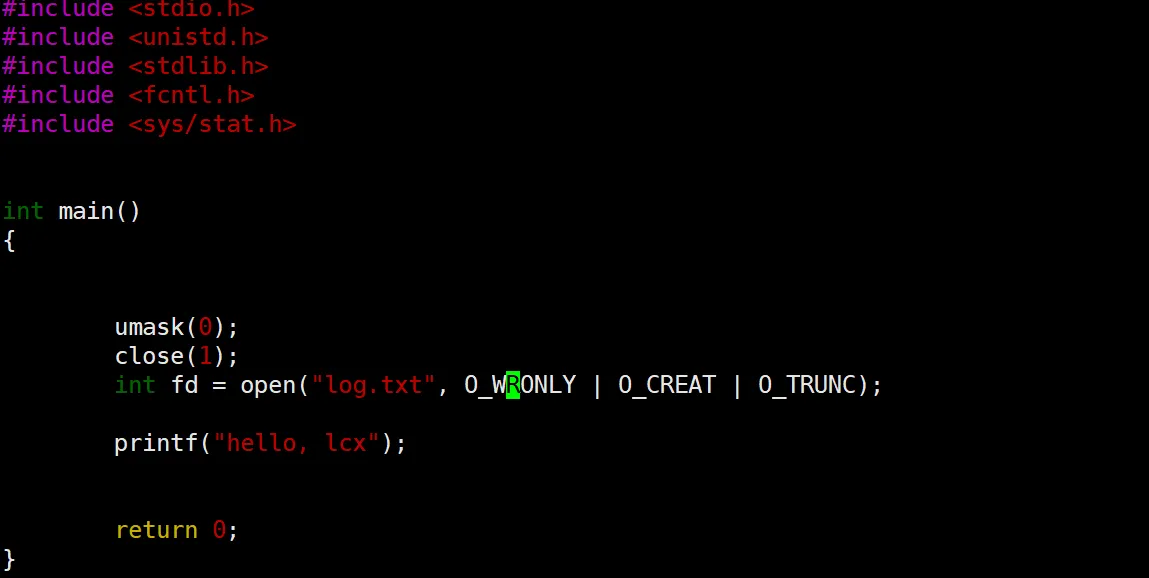
可以看到,我们把这个文件描述符 1 ,也就是 stdout 关了,然后新建一个 log.txt 打开,然后再输出,可以猜到屏幕上已经没有了,那么这个 hello 打印到哪里去了呢?

可以看到打到这个 log.txt 里面去了。(这里我忘敲回车了,黏糊糊的,嘻嘻)
这个现象是不是很像为我们的重定向操作,本来写道一个文件里面,然后写到别的文件里面了。我们这个现象出现是为社么你呢?首先,文件描述符的分配规则是从小到大,没被占用的先分配。由于我们已经拿 1 给关了,所以新来的这个 log.txt 就占上了 1 这个位置。
printf 这个函数呢打印的时候认死理,就要往文件描述符为 1 的文件里面打。所以,就有了上面这个现象。其实就是来了一波狸猫换太子。挺有趣的吧。
翻译成人话就是,数组下标没变,而数组这个位置的指针指向变了。这其实就是重定向的原理。
如果在刚才的代码后面加上一句,把这个log.txt 关掉,
会发现,什么也不会输出。这个涉及到后面讲缓冲区时候的事情,这里简单提一嘴。
每一个文件的 file 里面存储着文件的 inode 元信息,这个信息是什么呢?现阶段可以理解为就是除了文件名和文件内容,别的几乎都有,因为好多东西都没讲到,后期再谈
但是啊,刚才我们实现这个狸猫换太子,是先把这个 1 关上,然后再把这个 新文件打开,如果还有下一步的话就应该是把这个 1 打开,新文件关上。如果要重定向的文件多了,直接麻烦死了。
所以这个时候,就要有这个系统调用登场:
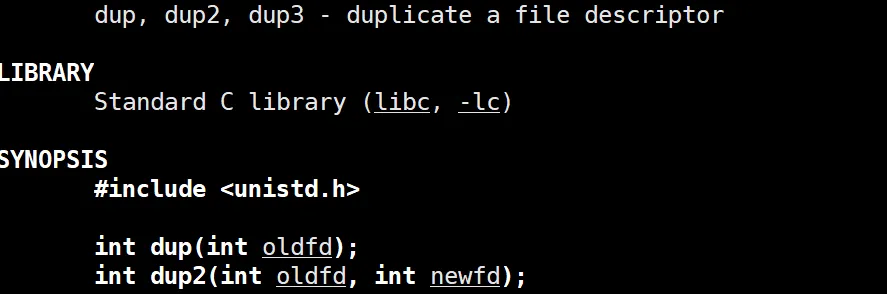
当当当当当,就是这个 dup2 奥,可以看到这个参数就是 新的fd 和 旧的 fd ,这个函数可以让 旧fd 位置的指针指向新新 fd 位置的 struct file。
返回值是成功了返回这个新位置的 fd ,失败了返回 -1 ,这只 errno。
还有一个问题,就以这个 stdin 和 新来的 log.txt 分别fd是 1 和 3 嘛,谁是 old 谁是 new ?

可以看到这个 dup2 这里有个描述, newfd 是 oldfd 的拷贝, 如果必要的话关闭 newfd ,所以 newfd 就是 1,而这个 oldfd 就是 3 。因为 1 位置的指针指向拷贝到了 3 位置了嘛。
所以 dup2(fd, 1)。 就是用法。
3.2 重定向原理再探
所以,重定向的完成其实就是 打开文件的方式 + dup2 。 后面我们给之气自己写的 minishell 加上这个重定向功能。但是还有一件事。我们 dup2 以后这个 fd 指针数组指向就不一样了。后续要怎么恢复呢?
如果我们是让子进程去执行这个重定向,那直接不用恢复了,跟着子进程自生自灭就好喽。为什么可以这样?子进程修改子进程 fd 指向会不会影响父进程?完全不会,因为进程是独立的,子进程创建拷贝了一份父进程,子进程修改自己的信息父进程拿不到,而如果修改共同信息的话会发生写实拷贝,也不会影响父进程,所以,让子进程去执行这个正好。
我们自己写 minishell 也是用的这个 原理 ,bash 是父进程嘛。
回顾一下我们之前讲进程等待的时候,为什么status是放在waitpid里面的输出型参数,而不是区全局变量,父进程拿不到子进程自己的变量,而且还有写实拷贝。
如果非要是父进程自己用这个dup2,要怎么调回来呢?其实会在这个数指针数组里面新开一个地方,先把这个 1 的指向存起来,等到结束了以后,再把 1 的指针指向换回去。 就想我们交换两个数那样整一个 tmp 变量。


